

learning lesson · Surgical Video AI · Lesson
Temporal Information: Why One Frame Is Rarely Enough
Published 7/13/2026
Course module: Implementation lens
Summary: How sequence, duration, transitions, and prior events change the interpretation of a surgical image.
Evidence status: Educational synthesis. This lesson explains research concepts and does not provide clinical guidance.
Estimated reading time: 8–11 minutes.
What you should be able to do:
- Define the central concept in language that works across clinical and technical teams.
- Identify how the concept is represented in surgical data.
- Recognize at least one common source of misleading evidence.
- Apply a practical review question to a surgical AI study.
Visual note: Conceptual illustration for orientation; it is not a clinical image or model output.
What the team must agree on
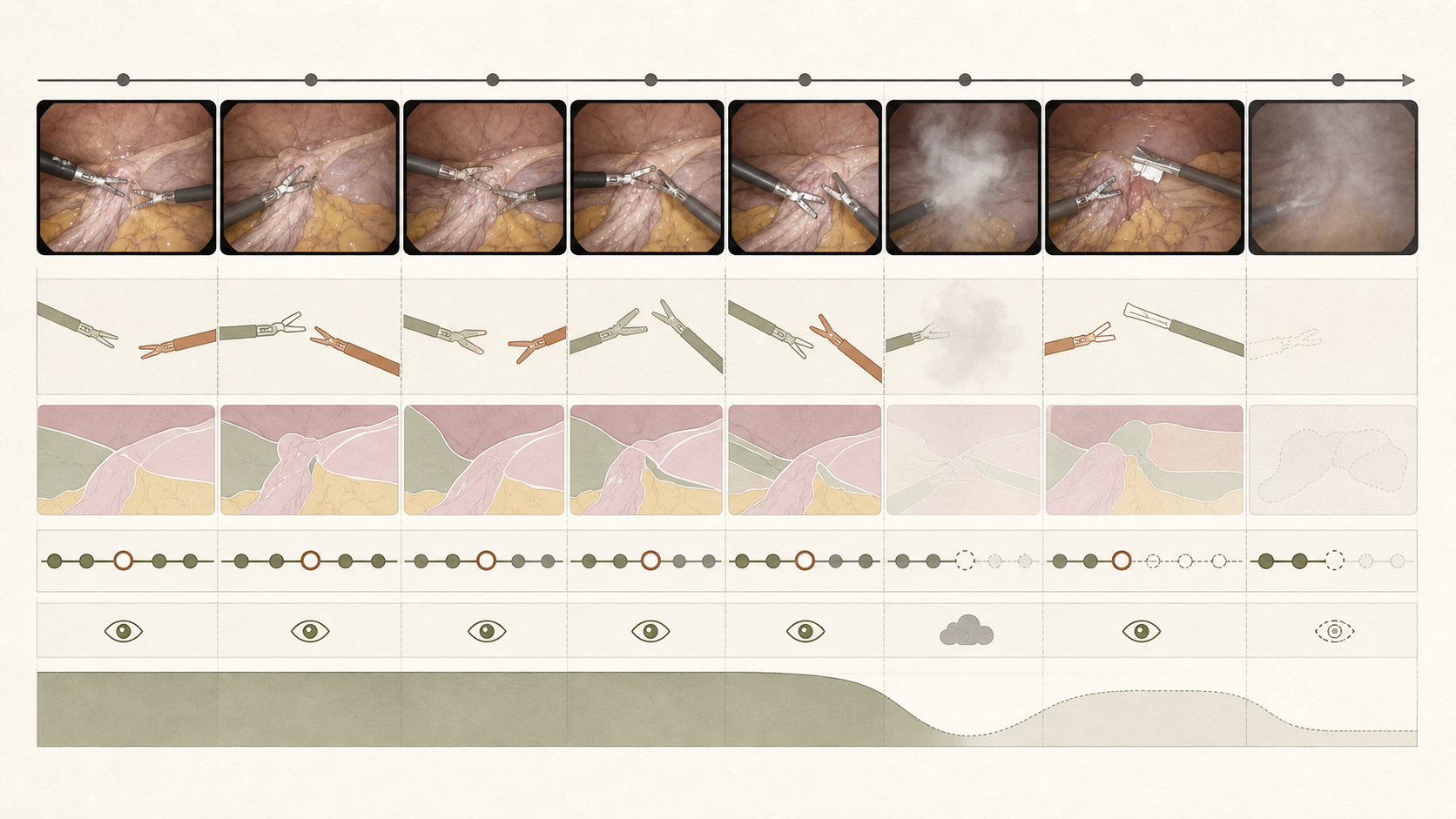
A frame records appearance at one instant. Surgical meaning often depends on motion, order, repetition, and the relationship between events. Temporal information can distinguish a brief tool crossing from sustained use and can separate visually similar phases.
The practical value of this distinction is that it keeps a project anchored to an observable question. Surgical AI work often becomes confusing when a technical output, a clinical interpretation, and a proposed intervention are described as though they were the same thing. They are connected, but each requires its own definitions and evidence. A reader should therefore ask what is being measured, how the reference label was created, and which conclusion the study design can legitimately support.[1,2]
For clinicians, this framing helps separate an interesting research result from something that could influence care. For engineers, it clarifies which assumptions depend on workflow, anatomy, or professional judgment rather than on code. The strongest projects make those assumptions visible early enough to test them.
Design choices that shape the evidence
Sequence models aggregate information over clips or entire procedures. Their design introduces choices about frame rate, window length, online versus offline inference, latency, memory, and whether future frames are allowed.
Every conversion from practice into data creates a representation. A representation can be useful without being complete, but its omissions should be documented. Frame sampling changes temporal detail. A category list simplifies continuous activity. A consensus label may hide disagreement. A benchmark split determines which forms of variation count as unseen. None of these choices is neutral, and none is necessarily wrong when it is aligned with a clearly stated purpose.
When reading or designing a study, trace the chain from source recording to final metric. Identify who selected the cases, what was excluded, how labels were defined, whether one patient or procedure could appear in more than one split, and what information the model did not receive. This chain often explains performance more clearly than the architecture diagram.
Operating-room scenario
A model reviewing an archived case may use frames before and after a transition. A real-time system cannot use future frames and must decide with incomplete evidence, so offline benchmark results may overstate live performance.
The example matters because surgical work is sequential and contextual. An isolated image may show an instrument or structure while omitting the reason it is present, the events that preceded it, and the options available to the team. A responsible interpretation states which part of the situation is visible in the data and which part remains a human clinical judgment.
The same technical output can also have different implications in different settings. A retrospective index used to find teaching clips tolerates delay and some errors. An intraoperative prompt may compete for attention and create a different risk. Intended use is therefore part of the technical specification, not a marketing statement added after training.
Translation boundary
Long windows can improve context but delay outputs and blur short events. Short windows react quickly but may confuse similar scenes. Evaluation should report temporal tolerance and delay, not only frame-level classification.
Evaluation should include difficult and ordinary conditions, not only clean examples. Useful analyses examine errors by center, surgeon, device, procedure stage, image quality, and relevant patient or case characteristics. They report uncertainty and avoid treating thousands of correlated frames as thousands of independent clinical observations. Where a model may encounter unsupported inputs, the ability to abstain can be more important than producing a label every time.[3]
Research prototypes should be described as prototypes. External validation tests transfer to a defined new setting; it does not prove universal performance. Prospective evaluation can reveal live operational problems; it does not automatically demonstrate patient benefit. Clinical impact requires a study designed around the decision, user, comparator, and outcome of interest.
Protocol exercise
Start with the clinical or operational question, then read the methods before accepting the headline result. Write down the unit of analysis: patient, procedure, clip, frame, instrument, or event. Check whether the train and test units are independent. Look for the number of centers and complete procedures rather than relying on image counts. Identify the reference standard and how disagreement was handled.
Next, inspect the metric and threshold. Ask which errors are hidden by averaging and whether the evaluation reflects online use, offline review, or selected frames. Finally, compare the conclusion with the experiment. A retrospective benchmark can support a statement about performance on that benchmark. It cannot by itself support routine clinical use.
Common misunderstanding
The misunderstanding is that adding a recurrent network or transformer automatically solves time. The sampling strategy and intended operating mode are equally important.
Correcting this misunderstanding does not make the field less ambitious. It makes progress easier to interpret. Clear boundaries allow researchers to claim what they have actually shown, clinicians to identify the remaining evidence, and collaborators to decide which next experiment would be informative.
Applied exercise
Imagine that a multidisciplinary team proposes a study related to temporal information: why one frame is rarely enough. Before discussing architectures, write one sentence for each of the following:
- The intended user and the decision or review task.
- The independent unit of data: patient, procedure, clip, frame, event, or another unit.
- The reference label and who is qualified to assign it.
- The most important condition under which the output may be wrong.
- The evidence boundary: retrospective feasibility, external validation, prospective observation, or clinical impact.
Compare the five sentences. If they describe different problems, the project is not yet sufficiently specified. This short exercise is useful in protocol meetings because it exposes disagreement before teams invest in annotation or model training.
Knowledge check
Question 1: Why is a technically accurate prediction not automatically useful? Answer: Usefulness depends on the intended user, timing, decision, consequences of error, and whether the output adds information that can be acted on safely.
Question 2: What should you inspect before comparing model architectures? Answer: Inspect the clinical question, data provenance, unit of analysis, annotation protocol, split strategy, exclusions, and intended-use conditions.
Question 3: What is the safest conclusion when a relevant setting was not evaluated? Answer: Performance in that setting remains uncertain. Lack of testing is neither proof of failure nor evidence of reliable transfer.
Key takeaways
- Define the intended question before selecting the model or metric.
- Treat labels and datasets as designed clinical-technical artifacts, not neutral ground truth.
- Count independent procedures, people, and centers, not only frames.
- Separate retrospective prediction performance from prospective workflow evidence.
- Report uncertainty, difficult conditions, and unsupported inputs explicitly.
- Keep research prototypes distinct from validated clinical systems.
Working glossary
- Intended use: The specific user, input, output, setting, and purpose for which a system is designed.
- Reference standard: The procedure used to create the labels against which an output is evaluated.
- External validation: Evaluation on data that cross a meaningful boundary from the development data, such as a new institution, device, or time period.
Suggested next lesson: Out-of-Body Frames, Smoke, Blood, Occlusion, and Other Practical Problems
Track: Surgical Video AI. Lesson 3 of 6.
Tags: temporal-modeling, online-inference, video.
References
- Surgical Data Science — from Concepts toward Clinical Translation. https://doi.org/10.1016/j.media.2021.102306
- Surgical Data Science: A Consensus Perspective. https://arxiv.org/abs/1806.03184
- EndoNet: A Deep Architecture for Recognition Tasks on Laparoscopic Videos. https://doi.org/10.1109/TMI.2016.2593957
- TeCNO for Online Recognition of Surgical Phases. https://arxiv.org/abs/2003.10751
- Endoscapes: A Critical View of Safety Dataset for Laparoscopic Cholecystectomy. https://arxiv.org/abs/2312.12429
- Segment Anything. https://arxiv.org/abs/2304.02643